What Does It Mean When Text Message Has Number Plus Number Again With (*)
Tutorial: Text Classification in Python Using spaCy
Published: April xvi, 2019

Text is an extremely rich source of data. Each minute, people send hundreds of millions of new emails and text letters. There'south a veritable mountain of text information waiting to be mined for insights. But information scientists who want to glean significant from all of that text data face a challenge: information technology is difficult to clarify and process because it exists in unstructured grade.
In this tutorial, nosotros'll accept a look at how we can transform all of that unstructured text data into something more useful for analysis and tongue processing, using the helpful Python packet spaCy (documentation).
One time nosotros've done this, we'll be able to derive meaningful patterns and themes from text data. This is useful in a wide variety of information science applications: spam filtering, support tickets, social media assay, contextual advertizement, reviewing customer feedback, and more.
Specifically, we're going to have a loftier-level look at natural language processing (NLP). Then nosotros'll work through some of the important bones operations for cleaning and analyzing text data with spaCy. So we'll swoop into text classification, specifically Logistic Regression Classification, using some real-world information (text reviews of Amazon'due south Alexa smart home speaker).
What is Natural Language Processing?
Natural language processing (NLP) is a co-operative of machine learning that deals with processing, analyzing, and sometimes generating human speech ("natural linguistic communication").
There's no doubt that humans are notwithstanding much better than machines at deterimining the meaning of a cord of text. But in data science, we'll often see information sets that are far as well big to be analyzed by a human in a reasonable amount of time. We may also encounter situations where no human is available to analyze and reply to a piece of text input. In these situations, we tin can use natural linguistic communication processing techniques to assist machines go some understanding of the text's meaning (and if necessary, respond accordingly).
For example, natural language processing is widely used in sentiment analysis, since analysts are ofttimes trying to determine the overall sentiment from huge volumes of text data that would be time-consuming for humans to comb through. It's also used in advertisement matching—determining the subject of a trunk of text and assigning a relevant advertisement automatically. And it's used in chatbots, voice assistants, and other applications where machines need to sympathise and rapidly respond to input that comes in the form of natural human linguistic communication.
Analyzing and Processing Text With spaCy
spaCy is an open up-source tongue processing library for Python. It is designed particularly for production utilise, and it tin aid usa to build applications that process massive volumes of text efficiently. First, let's take a await at some of the basic belittling tasks spaCy can handle.
Installing spaCy
We'll need to install spaCy and its English-language model before proceeding farther. We tin can exercise this using the following command line commands:
pip install spacy
python -k spacy download en
We can also apply spaCy in a Juypter Notebook. It'southward non one of the pre-installed libraries that Jupyter includes by default, though, then we'll need to run these commands from the notebook to get spaCy installed in the correct Anaconda directory. Note that nosotros use ! in front of each command to let the Jupyter notebook know that it should exist read as a command line command.
!pip install spacy
!python -yard spacy download en
Tokenizing the Text
Tokenization is the process of breaking text into pieces, called tokens, and ignoring characters similar punctuation marks (,. " ') and spaces. spaCy's tokenizer takes input in form of unicode text and outputs a sequence of token objects.
Let'due south accept a expect at a simple example. Imagine nosotros have the following text, and we'd like to tokenize it:
When learning data science, you shouldn't get discouraged.
Challenges and setbacks aren't failures, they're merely part of the journey.
There are a couple of different ways nosotros can appoach this. The first is called discussion tokenization, which means breaking up the text into individual words. This is a critical step for many language processing applications, as they often require input in the form of individual words rather than longer strings of text.
In the code below, we'll import spaCy and its English-language model, and tell information technology that we'll be doing our natural language processing using that model. Then we'll assign our text string to text. Using nlp(text), we'll process that text in spaCy and assign the upshot to a variable called my_doc.
At this point, our text has already been tokenized, simply spaCy stores tokenized text every bit a doc, and we'd like to look at information technology in list form, so nosotros'll create a for loop that iterates through our dr., adding each give-and-take token information technology finds in our text string to a list called token_list so that we tin accept a improve expect at how words are tokenized.
# Word tokenization from spacy.lang.en import English # Load English tokenizer, tagger, parser, NER and word vectors nlp = English() text = """When learning data science, you lot shouldn't become discouraged! Challenges and setbacks aren't failures, they're just office of the journeying. Y'all've got this!""" # "nlp" Object is used to create documents with linguistic annotations. my_doc = nlp(text) # Create listing of word tokens token_list = [] for token in my_doc: token_list.append(token.text) print(token_list) ['When', 'learning', 'data', 'science', ',', 'y'all', 'should', "north't", 'become', 'discouraged', '!', '\n', 'Challenges', 'and', 'setbacks', 'are', "n't", 'failures', ',', 'they', "'re", 'but', 'part', 'of', 'the', 'journey', '.', 'You', "'ve", 'got', 'this', '!'] As nosotros can see, spaCy produces a listing that contains each token equally a split up particular. Notice that it has recognized that contractions such equally shouldn't really represent 2 distinct words, and information technology has thus broken them downwardly into two distinct tokens.
Fist we need to load language dictionaries, Hither in abve instance, we are loading english dictionary using English() class and creating nlp nlp object. "nlp" object is used to create documents with linguistic annotations and various nlp backdrop. After creating document, we are creating a token list.
If we want, nosotros tin can also intermission the text into sentences rather than words. This is called sentence tokenization. When performing sentence tokenization, the tokenizer looks for specific characters that fall between sentences, like periods, exclaimation points, and newline characters. For judgement tokenization, we will use a preprocessing pipeline considering sentence preprocessing using spaCy includes a tokenizer, a tagger, a parser and an entity recognizer that we demand to access to correctly identify what's a sentence and what isn't.
In the lawmaking below,spaCy tokenizes the text and creates a Doc object. This Doc object uses our preprocessing pipeline'due south components tagger,parser and entity recognizer to break the text down into components. From this pipeline we can extract any component, but here we're going to admission sentence tokens using the sentencizer component.
# sentence tokenization # Load English tokenizer, tagger, parser, NER and word vectors nlp = English() # Create the pipeline 'sentencizer' component sbd = nlp.create_pipe('sentencizer') # Add the component to the pipeline nlp.add_pipe(sbd) text = """When learning data science, you shouldn't get discouraged! Challenges and setbacks aren't failures, they're merely part of the journey. You've got this!""" # "nlp" Object is used to create documents with linguistic annotations. doc = nlp(text) # create list of sentence tokens sents_list = [] for sent in doctor.sents: sents_list.suspend(sent.text) print(sents_list) ["When learning data science, you shouldn't get discouraged!", "\nChallenges and setbacks aren't failures, they're just part of the journeying.", "You've got this!"] Again, spaCy has correctly parsed the text into the format nosotros want, this time outputting a list of sentences found in our source text.
Cleaning Text Data: Removing Stopwords
Well-nigh text information that nosotros piece of work with is going to contain a lot of words that aren't actually useful to us. These words, chosen stopwords, are useful in man speech, but they don't accept much to contribute to data assay. Removing stopwords helps u.s. eliminate noise and distraction from our text information, and also speeds upward the time analysis takes (since there are fewer words to procedure).
Allow's take a expect at the stopwords spaCy includes by default. Nosotros'll import spaCy and assign the stopwords in its English-language model to a variable chosen spacy_stopwords so that we can have a wait.
#Stop words #importing finish words from English language. import spacy spacy_stopwords = spacy.lang.en.stop_words.STOP_WORDS #Printing the total number of stop words: print('Number of stop words: %d' % len(spacy_stopwords)) #Printing kickoff ten stop words: print('Get-go 10 stop words: %s' % list(spacy_stopwords)[:twenty]) Number of terminate words: 312 Beginning x stop words: ['was', 'various', 'l', "'s", 'used', 'once', 'because', 'himself', 'can', 'proper name', 'many', 'seems', 'others', 'something', 'anyhow', 'nowhere', 'serious', 'forty', 'he', 'at present'] As nosotros tin see, spaCy'due south default list of stopwords includes 312 total entries, and each entry is a single give-and-take. We tin also see why many of these words wouldn't exist useful for information analysis. Transition words like withal, for example, aren't necessary for agreement the basic meaning of a sentence. And other words like somebody are too vague to be of much use for NLP tasks.
If we wanted to, we could as well create our own customized listing of stopwords. Only for our purposes in this tutorial, the default listing that spaCy provides will be fine.
Removing Stopwords from Our Data
At present that we've got our list of stopwords, let'southward use it to remove the stopwords from the text string nosotros were working on in the previous section. Our text is already stored in the variable text, and so we don't demand to define that again.
Instead, nosotros'll create an empty listing called filtered_sent and then iterate through our doctor variable to await at each tokenized word from our source text. spaCy includes a bunch of helpful token attributes, and we'll utilise one of them called is_stop to place words that aren't in the stopword list and and so suspend them to our filtered_sent list.
from spacy.lang.en.stop_words import STOP_WORDS #Implementation of cease words: filtered_sent=[] # "nlp" Object is used to create documents with linguistic annotations. doc = nlp(text) # filtering finish words for word in doc: if word.is_stop==False: filtered_sent.suspend(word) print("Filtered Sentence:",filtered_sent) Filtered Judgement: [learning, data, science, ,, discouraged, !, , Challenges, setbacks, failures, ,, journey, ., got, !] Information technology'due south non also difficult to see why stopwords tin can be helpful. Removing them has boiled our original text downwardly to just a few words that give us a good idea of what the sentences are discussing: learning data science, and discouraging challenges and setbacks along that journey.
Lexicon Normalization
Lexicon normalization is another stride in the text data cleaning process. In the large picture, normalization converts high dimensional features into low dimensional features which are advisable for any machine learning model. For our purposes hither, we're only going to wait at lemmatization, a way of processing words that reduces them to their roots.
Lemmatization
Lemmatization is a way of dealing with the fact that while words like connect, connection, connecting, continued, etc. aren't exactly the same, they all have the same essential meaning: connect. The differences in spelling accept grammatical functions in spoken language, but for car processing, those differences can be disruptive, so nosotros demand a way to alter all the words that are forms of the word connect into the give-and-take connect itself.
One method for doing this is called stemming. Stemming involves simply lopping off easily-identified prefixes and suffixes to produce what'due south often the simplest version of a give-and-take. Connection, for example, would have the -ion suffix removed and be correctly reduced to connect. This kind of simple stemming is often all that'southward needed, but lemmatization—which actually looks at words and their roots (called lemma) every bit described in the dictionary—is more precise (as long every bit the words be in the lexicon).
Since spaCy includes a build-in way to suspension a word down into its lemma, we can just utilize that for lemmatization. In the following very simple instance, we'll use .lemma_ to produce the lemma for each word we're analyzing.
# Implementing lemmatization lem = nlp("run runs running runner") # finding lemma for each give-and-take for give-and-take in lem: impress(word.text,discussion.lemma_) run run runs run running run runner runner Part of speech (POS) Tagging
A discussion's part of voice communication defines its office within a sentence. A noun, for case, identifies an object. An adjective describes an object. A verb describes action. Identifying and tagging each discussion's function of speech in the context of a sentence is called Function-of-Spoken communication Tagging, or POS Tagging.
Let's try some POS tagging with spaCy! Nosotros'll need to import its en_core_web_sm model, because that contains the dictionary and grammatical information required to do this analysis. Then all we need to do is load this model with .load() and loop through our new docs variable, identifying the function of speech communication for each word using .pos_.
(Notation the u in u"All is well that ends well." signifies that the string is a Unicode string.)
# POS tagging # importing the model en_core_web_sm of English for vocabluary, syntax & entities import en_core_web_sm # load en_core_web_sm of English for vocabluary, syntax & entities nlp = en_core_web_sm.load() # "nlp" Objectis used to create documents with linguistic annotations. docs = nlp(u"All is well that ends well.") for word in docs: print(word.text,give-and-take.pos_) All DET is VERB well ADV that DET ends VERB well ADV . PUNCT Hooray! spaCy has correctly identified the part of speech for each word in this sentence. Being able to place parts of speech communication is useful in a multifariousness of NLP-related contexts, because it helps more than accurately understand input sentences and more than accurately construct output responses.
Entity Detection
Entity detection, also called entity recognition, is a more advanced form of language processing that identifies important elements like places, people, organizations, and languages inside an input cord of text. This is really helpful for quickly extracting information from text, since yous can quickly pick out important topics or indentify key sections of text.
Let'southward effort out some entity detection using a few paragraphs from this recent article in the Washington Post. Nosotros'll use .label to catch a label for each entity that's detected in the text, so we'll take a look at these entities in a more visual format using spaCy's displaCy visualizer.
#for visualization of Entity detection importing displacy from spacy: from spacy import displacy nytimes= nlp(u"""New York Urban center on Tuesday declared a public health emergency and ordered mandatory measles vaccinations among an outbreak, becoming the latest national wink point over refusals to inoculate against dangerous diseases. At least 285 people have contracted measles in the metropolis since September, mostly in Brooklyn'south Williamsburg neighborhood. The society covers four Zero codes there, Mayor Bill de Blasio (D) said Tuesday. The mandate orders all unvaccinated people in the area, including a concentration of Orthodox Jews, to receive inoculations, including for children as young as six months old. Anyone who resists could be fined up to $1,000.""") entities=[(i, i.label_, i.label) for i in nytimes.ents] entities [(New York City, 'GPE', 384), (Tuesday, 'Appointment', 391), (At least 285, 'Cardinal', 397), (September, 'DATE', 391), (Brooklyn, 'GPE', 384), (Williamsburg, 'GPE', 384), (four, 'Key', 397), (Nib de Blasio, 'PERSON', 380), (Tuesday, 'DATE', 391), (Orthodox Jews, 'NORP', 381), (six months old, 'Appointment', 391), (upwards to $ane,000, 'MONEY', 394)] Using this technique, we can identify a multifariousness of entities inside the text. The spaCy documentation provides a full list of supported entity types, and we can see from the brusque instance above that it's able to identify a multifariousness of different entity types, including specific locations (GPE), date-related words (Appointment), important numbers (CARDINAL), specific individuals (PERSON), etc.
Using displaCy we can also visualize our input text, with each identified entity highlighted by color and labeled. We'll use style = "ent" to tell displaCy that we want to visualize entities here.
displacy.render(nytimes, style = "ent",jupyter = Truthful) New York City GPE on Tuesday DATE declared a public wellness emergency and ordered mandatory measles vaccinations among an outbreak, becoming the latest national flash point over refusals to inoculate against dangerous diseases. At least 285 Central people have contracted measles in the city since September DATE , by and large in Brooklyn GPE 'south Williamsburg GPE neighborhood. The order covers 4 Fundamental Zip codes at that place, Mayor Neb de Blasio PERSON (D) said Tuesday Date .The mandate orders all unvaccinated people in the area, including a concentration of Orthodox Jews NORP , to receive inoculations, including for children equally immature as 6 months old Engagement . Anyone who resists could be fined up to $1,000 Coin .
Dependency Parsing
Depenency parsing is a language processing technique that allows usa to better make up one's mind the meaning of a sentence by analyzing how it'south constructed to determine how the individual words relate to each other.
Consider, for example, the sentence "Bill throws the brawl." Nosotros accept two nouns (Bill and brawl) and 1 verb (throws). But we can't only look at these words individually, or we may end upwardly thinking that the ball is throwing Bill! To empathise the judgement correctly, we need to expect at the give-and-take order and judgement structure, not only the words and their parts of spoken communication.
Doing this is quite complicated, merely thankfully spaCy will take care of the work for us! Beneath, let's give spaCy another short sentence pulled from the news headlines. And so nosotros'll apply another spaCy chosen noun_chunks, which breaks the input downward into nouns and the words describing them, and iterate through each chunk in our source text, identifying the discussion, its root, its dependency identification, and which chunk it belongs to.
docp = nlp (" In pursuit of a wall, President Trump ran into ane.") for chunk in docp.noun_chunks: impress(clamper.text, chunk.root.text, chunk.root.dep_, chunk.root.head.text) pursuit pursuit pobj In a wall wall pobj of President Trump Trump nsubj ran This output can be a lilliputian bit difficult to follow, but since we've already imported the displaCy visualizer, we can use that to view a dependency diagraram using manner = "dep" that's much easier to understand:
displacy.render(docp, style="dep", jupyter= True) 
Of form, nosotros can also check out spaCy'south documentation on dependency parsing to get a ameliorate agreement of the different labels that might get applied to our text depending on how each sentence is intrepreted.
Word Vector Representation
When we're looking at words alone, it's difficult for a car to understand connections that a human would understand immediately. Engine and car, for example, have what might seem similar an obvious connection (cars run using engines), but that link is not so obvious to a reckoner.
Thankfully, there'due south a way we can stand for words that captures more of these sorts of connections. A word vector is a numeric representation of a word that commuicates its relationship to other words.
Each word is interpreted as a unique and lenghty array of numbers. You can think of these numbers as beingness something like GPS coordinates. GPS coordinates consist of 2 numbers (latitude and longitude), and if we saw 2 sets GPS coordinates that were numberically close to each other (like 43,-lxx, and 44,-lxx), we would know that those two locations were relatively close together. Word vectors work similarly, although in that location are a lot more than two coordinates assigned to each discussion, so they're much harder for a human to eyeball.
Using spaCy's en_core_web_sm model, permit'southward take a expect at the length of a vector for a single word, and what that vector looks like using .vector and .shape.
import en_core_web_sm nlp = en_core_web_sm.load() mango = nlp(u'mango') print(mango.vector.shape) impress(mango.vector) (96,) [ 1.0466383 -1.5323697 -0.72177905 -2.4700649 -0.2715162 one.1589639 1.7113379 -0.31615403 -two.0978343 1.837553 1.4681302 2.728043 -ii.3457408 -five.17184 -iv.6110015 -0.21236466 -0.3029521 4.220028 -0.6813917 2.4016762 -1.9546705 -0.85086954 1.2456163 1.5107994 0.4684736 three.1612053 0.15542296 ii.0598564 3.780035 4.6110964 0.6375268 -one.078107 -0.96647096 -1.3939928 -0.56914186 0.51434743 2.3150034 -0.93199825 -ii.7970662 -0.8540115 -3.4250052 iv.2857723 2.5058174 -two.2150877 0.7860181 3.496335 -0.62606215 -2.0213525 -iv.47421 1.6821622 -half-dozen.0789204 0.22800982 -0.36950028 -iv.5340714 -1.7978683 -2.080299 iv.125556 3.1852438 -three.286446 1.0892276 1.017115 1.2736416 -0.10613725 3.5102775 1.1902348 0.05483437 -0.06298041 0.8280688 0.05514218 0.94817173 -0.49377063 1.1512338 -0.81374085 -1.6104267 1.8233354 -two.278403 -2.1321895 0.3029334 -1.4510616 -one.0584296 -3.5698352 -0.13046083 -0.2668339 i.7826645 0.4639858 -0.8389523 -0.02689964 2.316218 5.8155413 -0.45935947 4.368636 1.6603007 -3.1823301 -1.4959551 -0.5229269 1.3637555 ] There'southward no way that a homo could await at that array and identify information technology equally pregnant "mango," but representing the word this mode works well for machines, because it allows us to represent both the word'south significant and its "proximity" to other like words using the coordinates in the array.
Text Nomenclature
Now that we've looked at some of the cool things spaCy can do in full general, let's look at at a bigger real-globe application of some of these natural linguistic communication processing techniques: text nomenclature. Quite often, we may detect ourselves with a set of text information that we'd like to classify according to some parameters (perhaps the subject of each snippet, for instance) and text nomenclature is what volition help us to exercise this.
The diagram below illustrates the big-picture show view of what we want to do when classifying text. Get-go, we excerpt the features we want from our source text (and whatsoever tags or metadata it came with), and and so nosotros feed our cleaned data into a machine learning algorithm that do the classification for us.
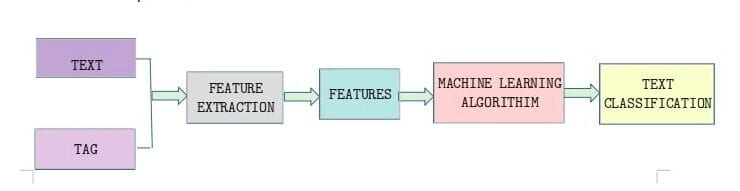
Importing Libraries
We'll showtime by importing the libraries we'll need for this task. We've already imported spaCy, simply we'll as well want pandas and scikit-learn to help with our assay.
import pandas every bit pd from sklearn.feature_extraction.text import CountVectorizer,TfidfVectorizer from sklearn.base import TransformerMixin from sklearn.pipeline import Pipeline Loading Data
Above, nosotros have looked at some uncomplicated examples of text analysis with spaCy, but now we'll be working on some Logistic Regression Classification using scikit-learn. To make this more than realistic, we're going to employ a real-globe data set up—this set of Amazon Alexa product reviews.
This data ready comes as a tab-separated file (.tsv). It has has five columns: rating, date, variation, verified_reviews, feedback.
rating denotes the rating each user gave the Alexa (out of v). date indicates the date of the review, and variation describes which model the user reviewed. verified_reviews contains the text of each review, and feedback contains a sentiment label, with 1 denoting positive sentiment (the user liked it) and 0 denoting negative sentiment (the user didn't).
This dataset has consumer reviews of amazon Alexa products like Echos, Echo Dots, Alexa Firesticks etc. What nosotros're going to do is develop a classification model that looks at the review text and predicts whether a review is positive or negative. Since this data set already includes whether a review is positive or negative in the feedback column, nosotros can use those answers to train and test our model. Our goal hither is to produce an accurate model that we could so utilise to procedure new user reviews and quickly determine whether they were positive or negative.
Let's start by reading the data into a pandas dataframe then using the congenital-in functions of pandas to help the states have a closer look at our data.
# Loading TSV file df_amazon = pd.read_csv ("datasets/amazon_alexa.tsv", sep="\t") # Meridian 5 records df_amazon.head() | rating | date | variation | verified_reviews | feedback | |
|---|---|---|---|---|---|
| 0 | 5 | 31-Jul-18 | Charcoal Fabric | Love my Echo! | ane |
| 1 | 5 | 31-Jul-18 | Charcoal Fabric | Loved information technology! | 1 |
| ii | 4 | 31-Jul-18 | Walnut Finish | Sometimes while playing a game, y'all tin can answer… | 1 |
| 3 | 5 | 31-Jul-eighteen | Charcoal Material | I have had a lot of fun with this thing. My four … | 1 |
| 4 | 5 | 31-Jul-18 | Charcoal Fabric | Music | 1 |
# shape of dataframe df_amazon.shape (3150, 5) # View information information df_amazon.info() <class 'pandas.cadre.frame.DataFrame'> RangeIndex: 3150 entries, 0 to 3149 Data columns (total 5 columns): rating 3150 not-null int64 date 3150 non-naught object variation 3150 non-null object verified_reviews 3150 non-nil object feedback 3150 not-null int64 dtypes: int64(ii), object(three) retentivity usage: 123.one+ KB # Feedback Value count df_amazon.feedback.value_counts() one 2893 0 257 Proper name: feedback, dtype: int64 Tokening the Data With spaCy
Now that we know what nosotros're working with, permit's create a custom tokenizer function using spaCy. We'll utilise this function to automatically strip information we don't need, similar stopwords and punctuation, from each review.
Nosotros'll start by importing the English language models we need from spaCy, as well as Python's string module, which contains a helpful list of all punctuation marks that nosotros can utilise in string.punctuation. We'll create variables that contain the punctuation marks and stopwords we want to remove, and a parser that runs input through spaCy'southward English language module.
And then, we'll create a spacy_tokenizer() function that accepts a sentence as input and processes the sentence into tokens, performing lemmatization, lowercasing, and removing stop words. This is similar to what we did in the examples earlier in this tutorial, but now we're putting information technology all together into a single function for preprocessing each user review we're analyzing.
import string from spacy.lang.en.stop_words import STOP_WORDS from spacy.lang.en import English # Create our listing of punctuation marks punctuations = string.punctuation # Create our list of stopwords nlp = spacy.load('en') stop_words = spacy.lang.en.stop_words.STOP_WORDS # Load English tokenizer, tagger, parser, NER and word vectors parser = English language() # Creating our tokenizer function def spacy_tokenizer(sentence): # Creating our token object, which is used to create documents with linguistic annotations. mytokens = parser(sentence) # Lemmatizing each token and converting each token into lowercase mytokens = [ discussion.lemma_.lower().strip() if word.lemma_ != "-PRON-" else give-and-take.lower_ for word in mytokens ] # Removing finish words mytokens = [ discussion for word in mytokens if discussion not in stop_words and word not in punctuations ] # render preprocessed list of tokens render mytokens Defining a Custom Transformer
To further clean our text data, we'll also want to create a custom transformer for removing initial and end spaces and converting text into lower case. Hither, nosotros will create a custom predictors class wich inherits the TransformerMixin form. This class overrides the transform, fit and get_parrams methods. Nosotros'll also create a clean_text() function that removes spaces and converts text into lowercase.
# Custom transformer using spaCy class predictors(TransformerMixin): def transform(self, 10, **transform_params): # Cleaning Text return [clean_text(text) for text in 10] def fit(self, X, y=None, **fit_params): render self def get_params(self, deep=True): return {} # Basic function to clean the text def clean_text(text): # Removing spaces and converting text into lowercase return text.strip().lower() Vectorization Feature Applied science (TF-IDF)
When we allocate text, we stop up with text snippets matched with their corresponding labels. Simply we can't but utilise text strings in our machine learning model; we demand a way to convert our text into something that can be represented numerically but similar the labels (i for positive and 0 for negative) are. Classifying text in positive and negative labels is chosen sentiment analysis. So we demand a style to correspond our text numerically.
I tool we tin can use for doing this is chosen Handbag of Words. BoW converts text into the matrix of occurrence of words within a given document. It focuses on whether given words occurred or not in the document, and it generates a matrix that we might come across referred to as a BoW matrix or a document term matrix.
We tin can generate a BoW matrix for our text data by using scikit-learn'due south CountVectorizer. In the lawmaking below, we're telling CountVectorizer to use the custom spacy_tokenizer function we built as its tokenizer, and defining the ngram range we want.
North-grams are combinations of adjacent words in a given text, where n is the number of words that incuded in the tokens. for case, in the sentence "Who will win the football world cup in 2022?" unigrams would be a sequence of single words such as "who", "will", "win" and then on. Bigrams would be a sequence of 2 contiguous words such as "who will", "will win", and and so on. So the ngram_range parameter nosotros'll apply in the lawmaking beneath sets the lower and upper premises of the our ngrams (we'll be using unigrams). Then we'll assign the ngrams to bow_vector.
bow_vector = CountVectorizer(tokenizer = spacy_tokenizer, ngram_range=(1,1)) We'll also want to look at the TF-IDF (Term Frequency-Inverse Document Frequency) for our terms. This sounds complicated, but it'south only a way of normalizing our Bag of Words(BoW) by looking at each word's frequency in comparison to the document frequency. In other words, it'due south a way of representing how important a particular term is in the context of a given certificate, based on how many times the term appears and how many other documents that aforementioned term appears in. The higher the TF-IDF, the more of import that term is to that document.
We tin can stand for this with the following mathematical equation:
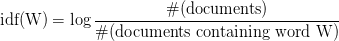
Of course, we don't have to summate that by manus! Nosotros can generate TF-IDF automatically using scikit-learn's TfidfVectorizer. Again, we'll tell it to use the custom tokenizer that we built with spaCy, and then we'll assign the result to the variable tfidf_vector.
tfidf_vector = TfidfVectorizer(tokenizer = spacy_tokenizer) Splitting The Data into Grooming and Test Sets
We're trying to build a classification model, only we need a fashion to know how it'southward actually performing. Dividing the dataset into a preparation set and a examination set the tried-and-true method for doing this. We'll apply half of our data prepare as our preparation set, which will include the right answers. Then we'll exam our model using the other half of the data set without giving information technology the answers, to see how accurately it performs.
Conveniently, scikit-learn gives united states of america a born function for doing this: train_test_split(). We just need to tell it the feature set we desire it to split (Ten), the labels nosotros want information technology to test against (ylabels), and the size we want to employ for the test set up (represented as a pct in decimal class).
from sklearn.model_selection import train_test_split X = df_amazon['verified_reviews'] # the features nosotros want to analyze ylabels = df_amazon['feedback'] # the labels, or answers, nosotros want to exam against X_train, X_test, y_train, y_test = train_test_split(X, ylabels, test_size=0.iii) Creating a Pipeline and Generating the Model
Now that we're all set up, it's time to really build our model! Nosotros'll start by importing the LogisticRegression module and creating a LogisticRegression classifier object.
So, nosotros'll create a pipeline with iii components: a cleaner, a vectorizer, and a classifier. The cleaner uses our predictors grade object to make clean and preprocess the text. The vectorizer uses countvector objects to create the handbag of words matrix for our text. The classifier is an object that performs the logistic regression to allocate the sentiments.
Once this pipeline is congenital, nosotros'll fit the pipeline components using fit().
# Logistic Regression Classifier from sklearn.linear_model import LogisticRegression classifier = LogisticRegression() # Create pipeline using Bag of Words pipage = Pipeline([("cleaner", predictors()), ('vectorizer', bow_vector), ('classifier', classifier)]) # model generation piping.fit(X_train,y_train) Pipeline(retention=None, steps=[('cleaner', <__main__.predictors object at 0x00000254DA6F8940>), ('vectorizer', CountVectorizer(analyzer='discussion', binary=False, decode_error='strict', dtype=<class 'numpy.int64'>, encoding='utf-eight', input='content', lowercase=Truthful, max_df=ane.0, max_features=None, min_df=1, ...ty='l2', random_state=None, solver='liblinear', tol=0.0001, verbose=0, warm_start=Fake))]) Evaluating the Model
Let'southward take a look at how our model actually performs! We can do this using the metrics module from scikit-learn. Now that we've trained our model, we'll put our test data through the pipeline to come up upward with predictions. Then nosotros'll use various functions of the metrics module to look at our model'due south accurateness, precision, and recall.
- Accuracy refers to the percentage of the full predictions our model makes that are completely right.
- Precision describes the ratio of true positives to true positives plus false positives in our predictions.
- Recall describes the ratio of truthful positives to true positives plus false negatives in our predictions.
The documentation links higher up offering more details and more precise definitions of each term, but the bottom line is that all 3 metrics are measured from 0 to one, where one is predicting everything completely correctly. Therefore, the closer our model'due south scores are to 1, the better.
from sklearn import metrics # Predicting with a test dataset predicted = pipe.predict(X_test) # Model Accuracy print("Logistic Regression Accuracy:",metrics.accuracy_score(y_test, predicted)) print("Logistic Regression Precision:",metrics.precision_score(y_test, predicted)) print("Logistic Regression Retrieve:",metrics.recall_score(y_test, predicted)) Logistic Regression Accuracy: 0.9417989417989417 Logistic Regression Precision: 0.9528508771929824 Logistic Regression Retrieve: 0.9863791146424518 In other words, overall, our model correctly identified a comment'south sentiment 94.ane% of the time. When it predicted a review was positive, that review was actually positive 95% of the time. When handed a positive review, our model identified it as positive 98.half dozen% of the time
Resources and Adjacent Steps
Over the course of this tutorial, we've gone from performing some very simple text analysis operations with spaCy to building our ain automobile learning model with scikit-learn. Of class, this is simply the beginning, and in that location'southward a lot more that both spaCy and scikit-learn take to offer Python data scientists.
Here are some links to a few helpful resources:
- Scikit-larn documentation
- spaCy documentation
- Dataquest's Machine Learning Course on Linear Regression in Python; many other machine learning courses are also available in our Data Scientist path.
Learn Python the Correct Manner.
Larn Python past writing Python lawmaking from solar day one, right in your browser window. It'due south the best manner to larn Python — encounter for yourself with one of our 60+ gratuitous lessons.

Try Dataquest
Tags
Source: https://www.dataquest.io/blog/tutorial-text-classification-in-python-using-spacy/
){kind=link}
Post a Comment for "What Does It Mean When Text Message Has Number Plus Number Again With (*)"